June 3, 2026
Kyla Guru, Alex Moix, and Jacob Klein
We’ve spent the past year investigating how threat actors are weaponizing AI to conduct cyber operations. Today, we’re sharing a new analysis that maps these real-world attacks onto the MITRE ATT&CK® framework, a database of tactics and techniques used by cyberattackers. Doing so reveals patterns that challenge traditional assumptions about cybersecurity—for example, the level of risk a threat actor poses can be assessed via metrics like technical sophistication or breadth of techniques. We partnered with Verizon to include some of these results in the 2026 Verizon Data Breach Investigation Report (DBIR), and are publishing this report to offer a longer-form analysis of trends we are seeing in AI-enabled cyber operations.[1]
Open the interactive Navigator in a new tab.
Key findings
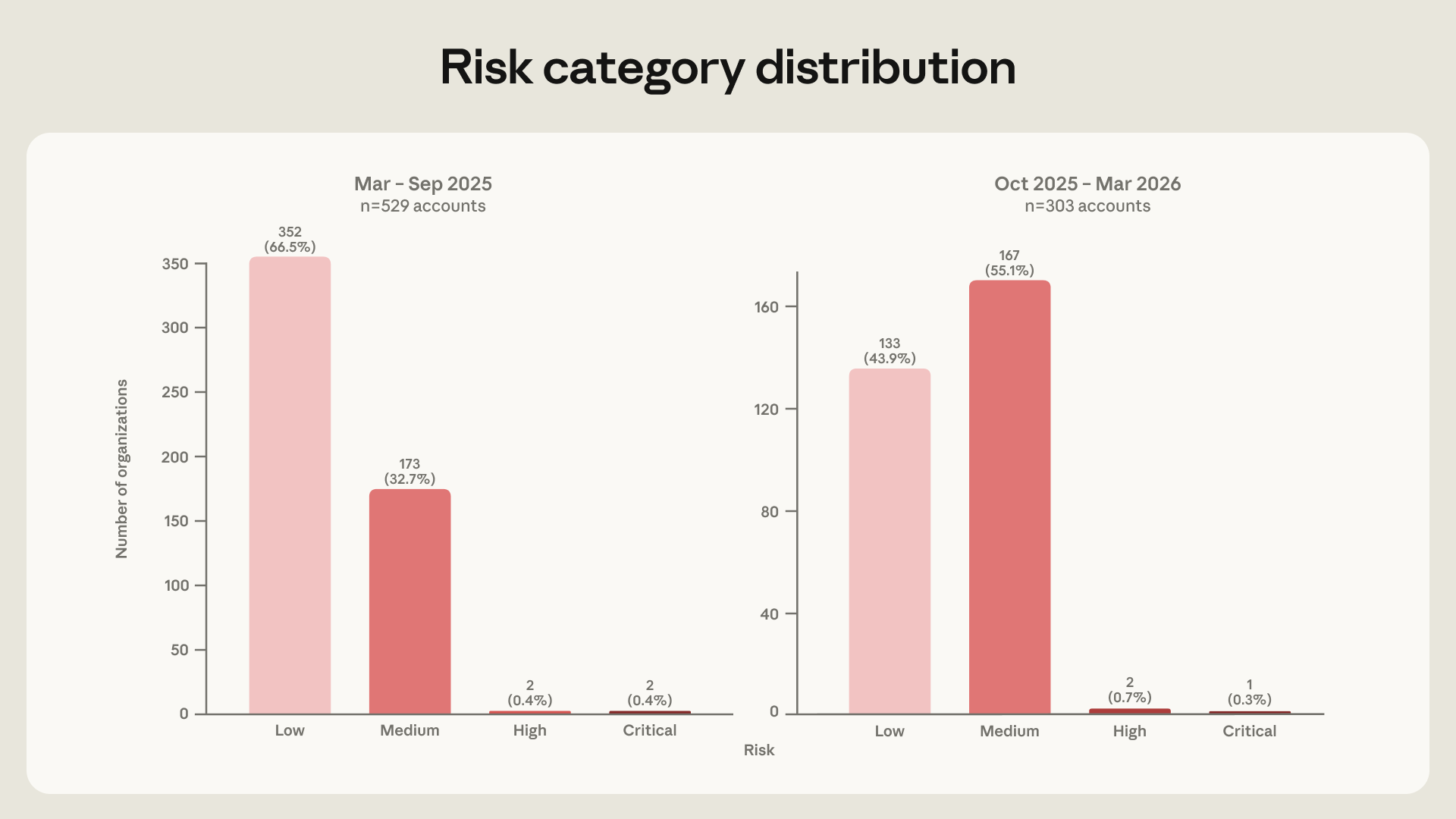
For this study, we analyzed 832 accounts associated with malicious cyber activity over the course of one year, from March 2025 to March 2026. Anthropic banned these accounts from using Claude for violating our Usage Policy. The accounts in this analysis are just a subset of those we investigated and banned during this time period; we selected them because we had enough detail about their malicious activities to map their techniques onto the MITRE ATT&CK framework.
The 832 accounts in our analysis used AI models for all 14 tactics and 482 unique sub-techniques across the framework, from initial reconnaissance through final impact.[2] We also developed a risk-scoring framework (described later in this post) to assess how much AI assistance helped these actors plan their attacks. Most strikingly, we found that the percentage of actors labeled as being medium risk or higher jumped from 33% to 56% between the first and second halves of the year. This suggests that AI is helping attackers conduct increasingly sophisticated cyber operations with greater ease.
There are three key findings from our analysis:
- The number of actors using AI for cyber operations is growing, and their actions carry higher risk. As mentioned above, the percentage of medium- or high-risk actors increased by a factor of about 1.7 in under a year, from 33% in the first half of our study window to 56% in the second. That growth is concentrated in actors using AI for some of the most harmful activities, including lateral movement, credential dumping, and web shells — that carry the highest per-actor risk weight in our scoring, rather than the commodity build-and-obfuscate work that dominates the rest of the population. Traditionally, only the most technically sophisticated actors could operate across the entire killchain, or the sequential stages of a cyberattack. But our analysis found that this is no longer the case. The platform through which they access the model (such as an API or an agentic coding platform like Claude Code) also has no bearing on how high-risk their actions are. What does distinguish the highest-risk actors is which techniques they’re asking the model for.
- Agentic scaffolding will make it possible for cyberattacks to be far more autonomous. As AI-enabled cyber techniques become more common among this population, it will become harder to differentiate an actor’s risk level based on what they are asking a model to do. Instead, the differentiator will become the scaffolding—the surrounding code, architecture, and tooling that makes AI models more capable—that actors build around the model so they can chain together attack stages autonomously. This was starkly apparent in the cyber espionage campaign we disrupted in November 2025, which had a maximum risk score of 100 yet only used a number of techniques comparable to medium-risk actors. That attack was distinct not because of the number of techniques it employed but because of how the attackers used an AI agent to orchestrate them.
- The MITRE ATT&CK framework doesn’t yet cover the autonomous actions that make these actors so dangerous. Autonomous killchain orchestration, real-time pivot decisions, and AI-directed execution with no human intervention don’t yet have ID numbers in the ATT&CK framework. Our report included 13,873 observations of malicious activity, all of which mapped to categories laid out in the framework—but the behaviors that distinguish the highest-risk actors, and determine the speed and scale of their operations, don’t yet have such IDs. The taxonomy that modern threat intelligence relies on needs to grow to capture them.
While Claude Mythos Preview demonstrates where frontier AI cyber capabilities are heading—models able to find and exploit vulnerabilities at a level approaching the most skilled human researchers—this report tells us how threat actors are misusing generally available models today. It also serves as a guide to how threat actors are likely to misuse increasingly capable models in the near future, giving defenders a chance to get ahead of them.
What we learned from this and other analyses directly shapes how we build Claude to prevent such misuse. For example, we’ve updated the classifiers built into Claude to detect the highest-risk actors, and have expanded our probe detections to cover high-risk behavioral indicators revealed by this analysis. These findings point to a landscape where the dividing line between low and high-risk actors is no longer technical skill but orchestration, and where defenses, detections, and the shared frameworks we all rely on will need to evolve as fast as the attacks they describe.
About the dataset
The findings in this report are drawn from 832 accounts that Anthropic banned for violating cyber-related parts of our Usage Policy between March 2025 and March 2026. We identified these accounts through a combination of automated safeguards and investigations by our Threat Intelligence team. For each account, we produced a summary of the observed activity. We then extracted the tactics, techniques, and procedures (or TTPs) described in those summaries, and mapped them to the version of the MITRE ATT&CK framework that was live at that time (V18). In all, we observed 13,873 actions across 482 unique techniques and all 14 ATT&CK tactics.
We gave each actor a risk score from 0 to 100 (with 0 being the lowest risk and 100 being the highest) based on a new methodology we’ve developed called the AI Risk Enablement Score (ARiES), described below. We’ve anonymized the data so that actors cannot be identified in the analysis that follows.
The LLM ATT&CK Navigator and ARiES risk score
As part of this analysis, we developed the LLM ATT&CK Navigator: an interactive framework that maps observed AI-enabled misuse patterns onto the MITRE ATT&CK framework and assigns an ARiES risk score to the actor. ARiES is a composite score built from three signals: the actor’s threat profile, the model’s contribution to the requested harm, and the observed or potential impact. It is calculated based on the actor's activity across Claude.ai, Claude Code, and our API, drawing on our safety classifiers alongside open-source and internal threat-intelligence indicators. The higher the score, the higher-risk the AI enabled actor is.
Our framework scores both individual techniques and accounts across three dimensions:
- Threat (0–35 points): Evaluates the clarity of the actor’s intent, their technical sophistication, threat intelligence signals, and tactics employed by the account to evade detection. Technical sophistication is graded by Claude on the basis of the actor's prompts and tool usage, measuring expertise required, operator skill, bespoke-versus-commodity tooling, and capability depth.
- Vulnerability (0–35 points): Assesses the model’s capacity to enable the requested harm and the risk profile of the interface used. Programmatic interfaces (i.e. API) and agentic coding tools like Claude Code score highest due to their potential to automate actions.
- Impact (0–30 points): Captures the real-world effects of the user’s behavior through scores assigned by our safety classifiers and investigators’ assessment of actual or potential consequences attributable to AI’s involvement in the operation.
Together, these components produce a total risk score from 0 to 100, allowing us to categorize threat actors and techniques into low, medium, high, and critical risk tiers.
A note on the scoring formula See moreSee less
Traditional cyber risk equations express risk as Threat × Vulnerability × Impact—a multiplicative model that reflects whether a hypothetical attack is likely to succeed. Under this model, if any one factor is zero, the overall risk collapses to zero, because a missing ingredient means the attack will not succeed.
Our model deliberately uses addition rather than multiplication so that we can answer the question, “Which AI-involved actors and techniques warrant the most attention from defenders?” We wanted a score that would remain meaningful even when one dimension is absent or unclear, which the multiplication model does not allow. Consider the following scenarios:
- High capability and consequence, but no clear intent. Imagine an inexperienced user who, through experimentation with an agentic coding tool, inadvertently produces functional offensive capabilities, like a wormable exploit. Intent is effectively zero, so a multiplicative score would register this as no risk. But in reality, the model has still provided substantial uplift to a potential attack, and the interaction is very much worth surfacing so that additional safeguards can be deployed.
- Clear intent and capability but no identified victim. Now consider an actor with explicit malicious intent who misuses Claude to develop working malware, but we have no evidence of deployment or downstream impact—yet. The multiplicative model would, again, zero out the score on the “impact” dimension, even though the AI enablement signal—the fact that an adversary was able to successfully develop harmful software using the model—is exactly what we want our detection systems to catch early.
By contrast, our additive model preserves signals from each dimension independently, meaning partial attack-enablement patterns remain visible. The tradeoff is that our scores are not predictions of whether an attack will be successful; rather, they are measures of how concerning an AI-involved misuse case is. As we will discuss below, we can also use these scores to see what specific parts of the ATT&CK framework are most concerning, and correlate these with where high-risk actors are operating.
How cyber threat actors are using AI today
Our empirical analysis of 13,873 observed techniques reveals clear patterns in how adversaries are using AI across the attack lifecycle, and the most common techniques that models are being used for today.
AI-assisted capability development
The most common technique family we observed was ATT&CK ID T1587 (Develop Capabilities), used by 574 of the 832 actors in our analysis, or 69%. The majority of this behavior manifests as T1587.001 (Malware Development), used by 560 actors. In practice, we observe threat actors misusing models to build and refine custom scripts to run, write DLL injection code with detailed guidance on how to implement it, as well as canvas fingerprinting evasion and automated account management.
The next most prevalent techniques are T1027 (Obfuscated Files or Information), employed by 64.7% of threat actors; T1005 (Data from Local System), employed by 55.9% of threat actors; and T1562 (Impair Defenses), employed by 54.9% of threat actors. Together, these top techniques show that threat actors most commonly seek LLM’s help to build pre-engagement offensive tooling, make those tools harder to detect, and harvest data from compromised systems.
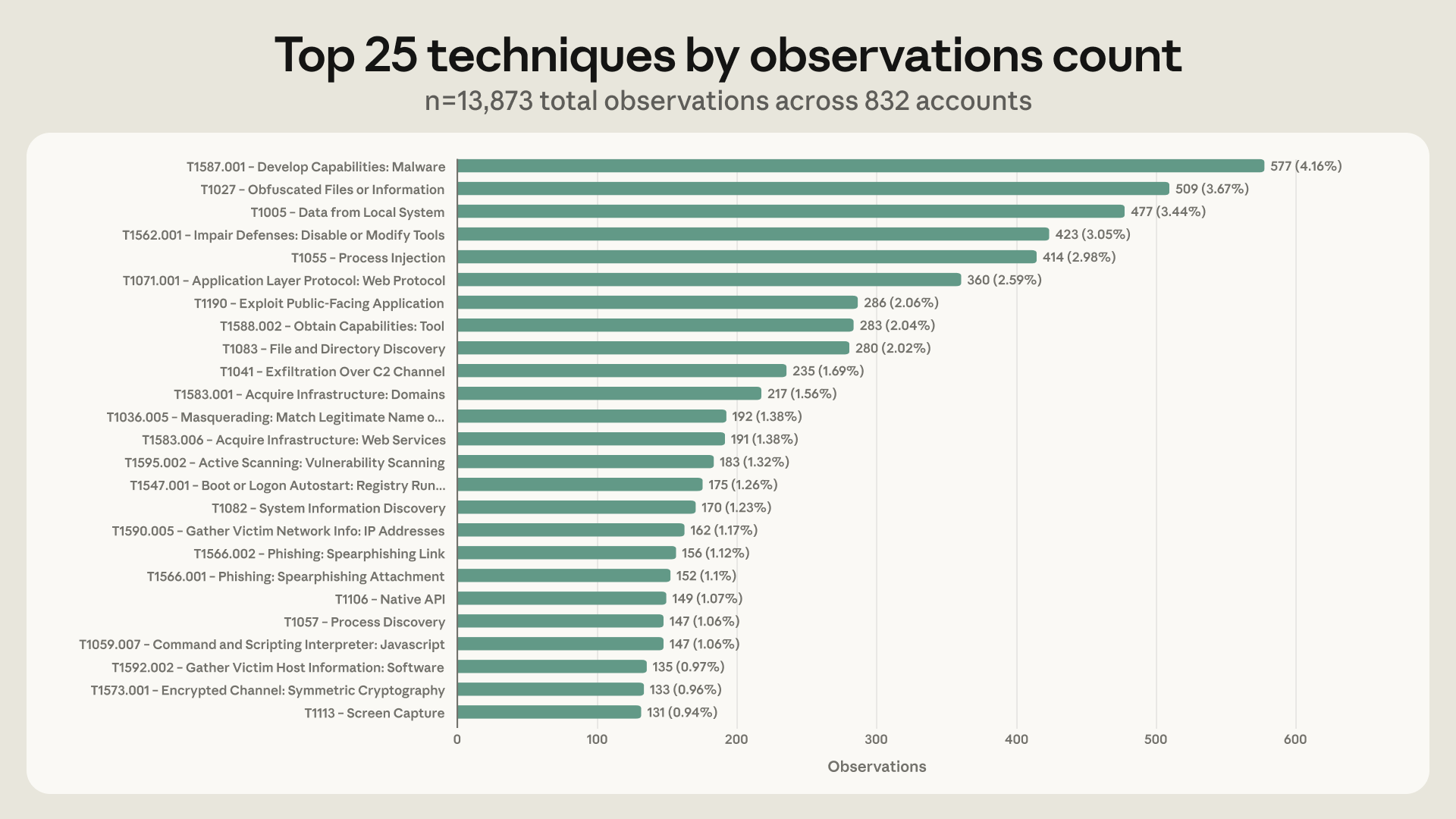
On the other hand, actors are much less likely to use LLMs for real-time, adaptive decision-making once they’ve gotten inside a target network. For example, only 54 of 832 threat actors (6.5%) use models for lateral movement, and less than 12 actors use models for remote services like RDP, SSH, and SMB. Only 22.5% of actors use LLMs for privilege escalation and impact stages.
Some technique families that are staples of real-world cyberattacks—such as active directory exploitation, Kerberos ticket attacks, cloud infrastructure manipulation (AWS, Azure, GCP), and container escape —have notably lower representation within the dataset.
The top techniques and the frequency with which actors used them didn’t change much over the one-year period we studied. For both the first and second halves of the period, the median number of techniques the model is used for is 16. In the second half of the year, we observe a subtle directional shift, with threat actors using models less to build standalone malware or obfuscation scripts and more to help with specific operational phases in a cyberattack, and for on-target discovery and collection techniques. Specifically, we observe an 8.9% increase in T1087 (Account Discovery) occurrences, as well as a 6.2% increase in T1020 (Automated Exfiltration), alongside a 12% decrease in T1587 (Develop Capabilities) and a 8.6% decrease in T1566 (Phishing).
AI-assisted evasion tactics
Defense evasion is the single largest tactic category in the dataset, present in the behavior of 84.4% of the actors we studied. MITRE defines 64 techniques under “defense evasion” (across its Enterprise- and Mobile-specific frameworks); we observe 32 of these techniques in our dataset: 25 for enterprise and 7 for mobile.
The top techniques observed within this tactic include:
- T1027 (Obfuscated Files or Information). 64.7% of threat actors in our sample used AI to implement techniques like XOR/base64 encoding, polymorphic variants, and anti-detection wrappers to evade signature-based detection.
- T1562 (Impair Defenses). 54.8% of the threat actors studied used AI to bypass, disable, or tamper endpoint security tools.
- T1055 (Process Injection). 30.3% of actors used AI to write malicious code that could be injected into legitimate processes, such as process hollowing and DLL injection, to execute payloads from trusted process memory.
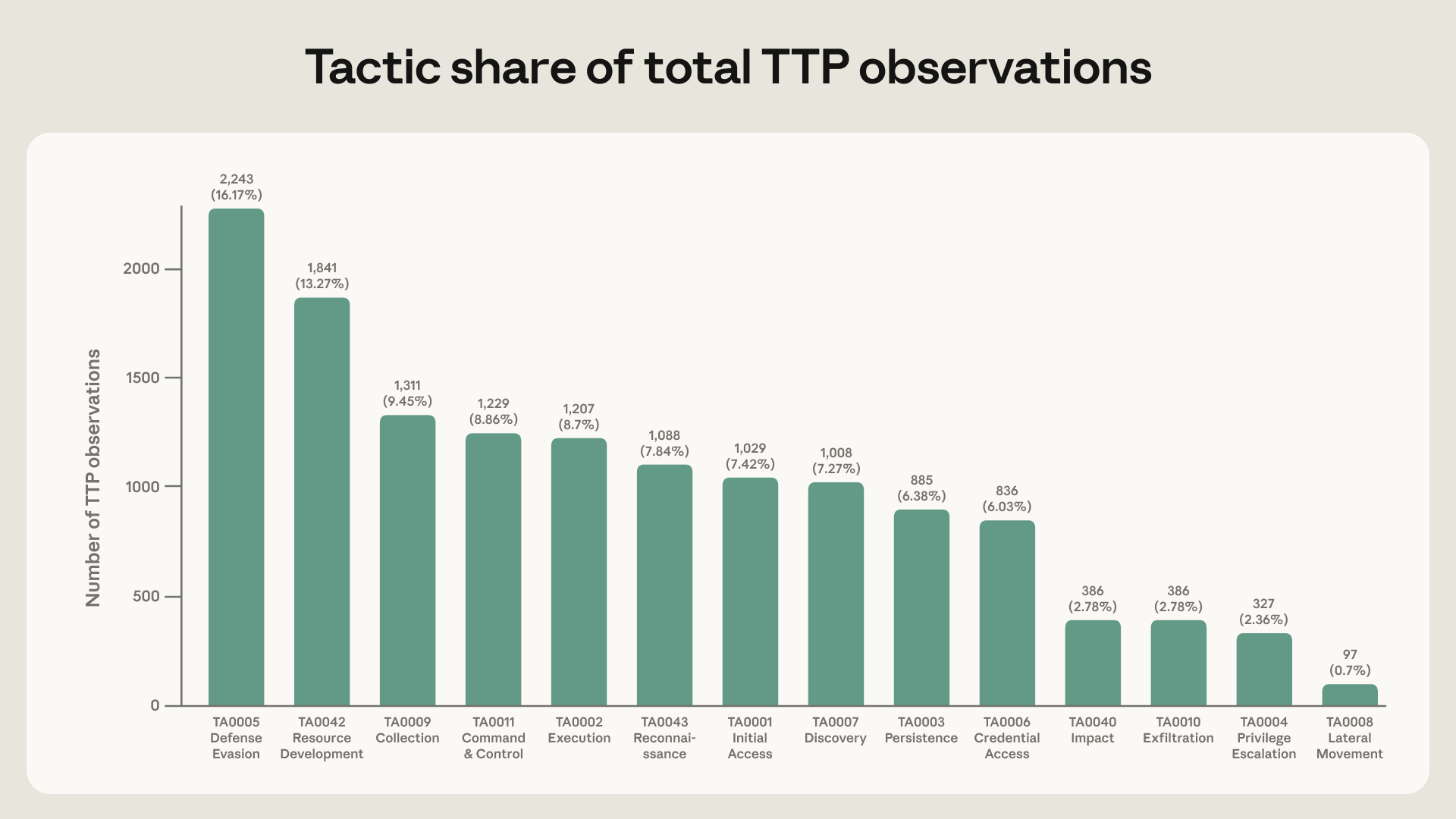
Less frequently used tactics include impact (2.8%), exfiltration (2.8%), privilege escalation (2.4%), and lateral movement (0.7%). Together, these account for just 8.7% of all observations—less than defense evasion alone. These actions all occur later in the attack life cycle, suggesting that threat actors are using models more in the early stages of an attack but less in the later stages—that is, once they have infiltrated a network and are adapting to conditions in a live environment. This pattern remained stable over the one-year period we studied.
High-risk actors and their tactics
While tactics such as lateral movement are much less prevalent in our dataset, they are highly correlated with the highest ARiES risk scores—meaning that the highest-risk actors are also the ones most likely to use models for the later stages of a cyberattack. Actors who use AI to perform lateral movement have risk scores that are, on average, 10.5 points higher than actors who do not use AI tools in this way. This suggests that going from using AI to prepare for a cyberattack to using it to take actions in live network operations is a key marker of high AI enablement.
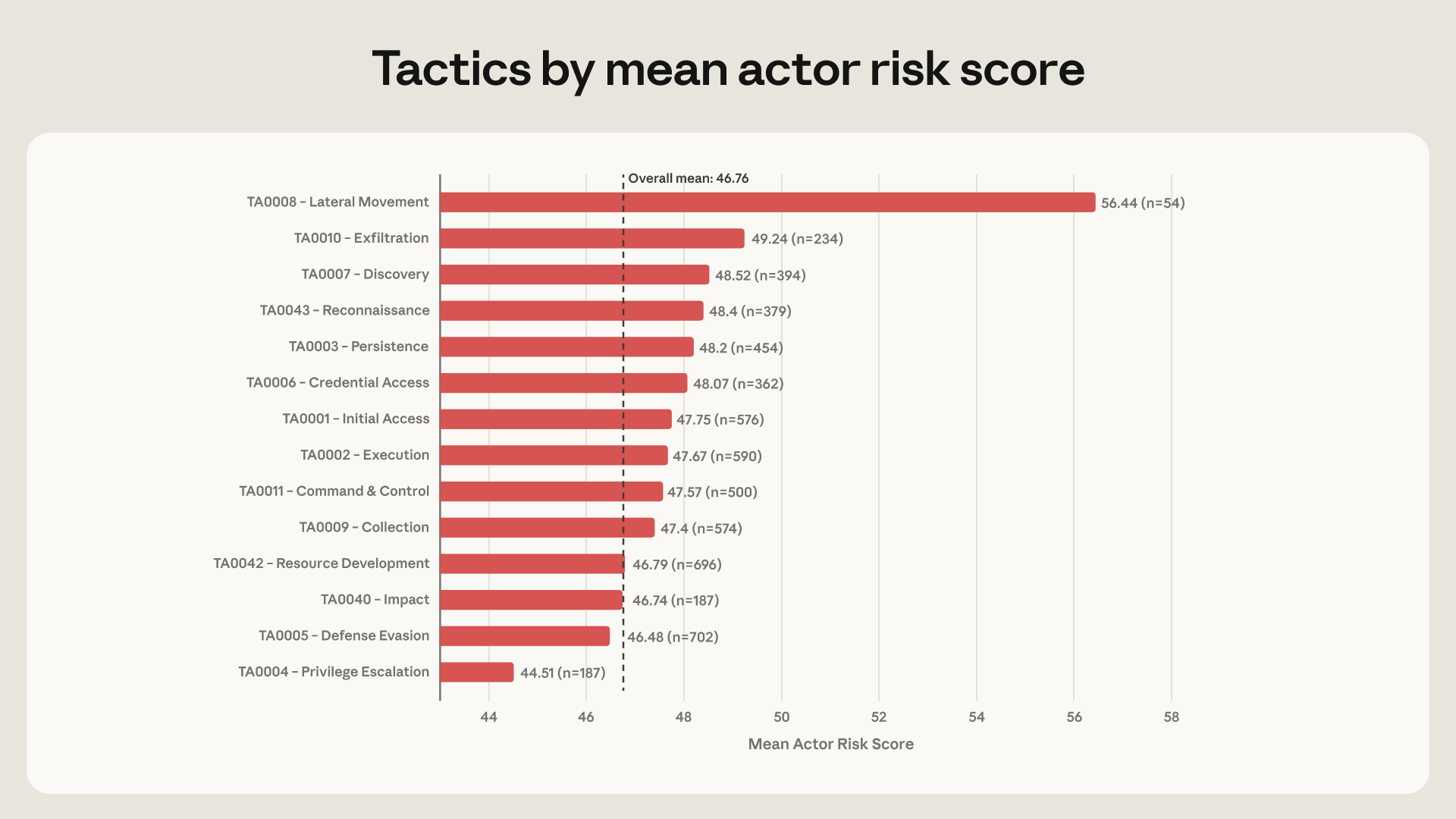
Overall, the actors with the highest risk scores used AI most heavily for post-compromise, hands-on-keyboard techniques, such as remote services, credential dumping, web shell deployment, and internal network and account discovery. Lateral movement was the strongest marker of a high-risk actor: the 54 actors in our dataset who used lateral movement had an average risk score of 56.4, nearly 10 points above the mean of 46.8. No other technique came close to having such predictive power.
At the technique level, the techniques that were most commonly used by the highest-risk actors were T1021 (Remote Services: SSH/SMB), T1078.003 (Valid Accounts), T1003 (OS Credential Dumping), T1560 (Archive Collected Data), and T1505.003 (Web Shell). These were all three to five times more common among the highest-risk actors compared to the overall population.
Meanwhile, the most ubiquitous tactics (such as defense evasion and resource development) and commodity techniques (such as credential stuffing and spearphishing) were used at roughly the same frequency by both the highest- and lowest-risk actors, which is unsurprising given that these tactics are so common. Taken together, the data suggests that the majority of threat actors are using AI to build artifacts like malicious code in the preparatory stages of an attack, but the highest-risk actors are using models both in the preparatory stages of an attack as well during the hands-on work inside a compromised network.
We also found that the attributes that threat-intelligence teams typically lean on to assess threat actors—such as their assessed technical skill, choice of interface, or number of techniques used—are weak predictors of how much uplift an AI model might provide to a given threat actor. Technical sophistication, once removed from the composite score to avoid circularity, correlates with the remaining risk components at only r = 0.28. In fact, removing this characteristic entirely leaves the top six actors in identical rank order (Spearman ρ = 0.96 across all 832). The high-risk tail is not an artifact of the Technical Sophistication component.
The correlation between breadth of technique coverage and risk score is also only weakly positive (r = 0.27). Most actors are using the models for a smattering of techniques – in fact, the median actor in our dataset deployed 16 distinct MITRE ATT&CK techniques—a breadth that, five years ago, may have signaled a well-resourced, technically mature operation.
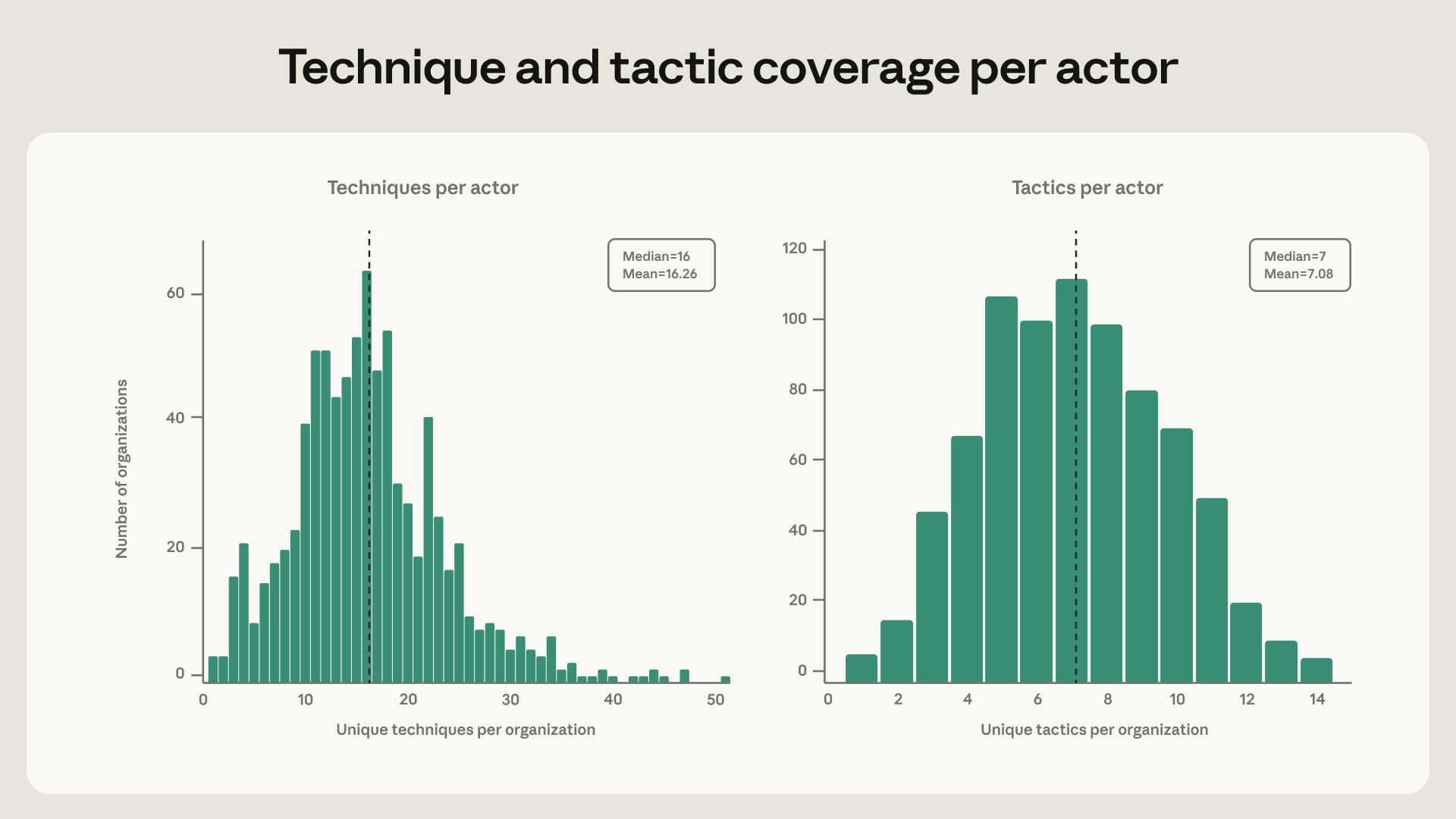
Lastly, interface choice tells a similar story — 80% of the actors in this study misused Claude Code, making agentic tooling the default mode of access rather than a distinguishing one, and actors restricted to the conversational interface, the API, or agentic coding tools converge on statistically indistinguishable risk profiles.
What this tells us is that the malicious actors who get the most uplift from AI are not necessarily more technically sophisticated than other actors, nor do they necessarily use coding tools or use Claude across multiple steps of the killchain; rather, they simply used Claude for more hands-on techniques.
Live exploitation actors on the rise
As we discussed above, the share of actors scoring medium-risk or higher on AI enablement grew from roughly 33.5% in the first six-month period of the study to roughly 56.1% in the second—a 1.7x increase in under a year. The cohort shifted between these two periods by about 22.6 percentage points: while the majority of actors had a low risk score in the first six-month period, the majority had a medium risk score in the second six-month period.
While improved threat detection techniques may have contributed to this increase, we also see an increasing number of actors asking the model for more operational, in-network work that used to appear only in a much smaller cohort of high-risk actors. In the second six-month period of the study, we saw more specialized actors using models to build exploitation tooling, C2 infrastructure, and remote access trojans —but we also saw more low- and mid-skill actors using models not just for preparatory tasks but for live operations. The 8.9% increase in T1087 (Account Discovery) and 6.2% increase in T1020 (Automated Exfiltration) techniques we observed from the first six-month period to the second are consistent with this: the techniques that are becoming more frequent are the ones that imply the actor has already accessed the network.
What this means for defenders: the population of AI-enabled actors is not only growing but also drifting towards the riskiest activities in our framework, without requiring the actors themselves to become any more skilled. If this trend continues, these operational techniques won’t be a differentiating factor anymore and will become the baseline tomorrow — and we’ll need to find a new way to measure the riskiest actors. In the next section, we’ll discuss how we might be able to do this going forward.
Novelty and sophistication in the age of AI agents
Looking at our highest-risk threat actors also underscores that calculating the risk of AI-enabled cyber operations based on number, type, or breadth of attack techniques is insufficient. We also need a way to understand the scaffolding threat actors are able to build to chain these techniques together to use in live operations, which allows them to use AI models to autonomously execute large swaths of a cyberattack without human intervention.
We analyzed the behavior of the threat actor who orchestrated the AI-enabled cyber espionage campaign we reported on in November 2025, labeled GTG-1002, we see that this actor achieved the maximum possible risk score of 100, successfully compromised government and critical infrastructure targets across multiple countries, and developed a scaffolding to use Claude Code not as an advisor, but as an autonomous operator. Yet their overall MITRE profile—30 techniques across 13 tactics—is comparable to dozens of medium-risk actors in this dataset. The median actor deploys 16 techniques; several low-risk actors also exceed 30. In other words, technique count or tactic type alone could not explain what made GTG-1002 the most high-risk actor we have observed thus far.
What does explain this actor’s high risk score is the increasingly agentic components they used: how they were able to orchestrate and chain together techniques to take action on their objectives. GTG-1002 weaponized Claude Code running on a Kali Linux machine, integrating open-source penetration testing tools as MCP (Model Context Protocol) servers—effectively turning the AI into an autonomous attack platform rather than a code-writing assistant. The AI didn't just suggest commands or generate attack scripts; it executed them and reasoned about attack environments autonomously. Some indications of their ‘agentic-ness’ show up proxied through the types of techniques we track; GTG-1002 employed operational techniques such as T1021.004 (Remote Services: SSH), T1210 (Exploitation of Remote Services), and T1560 (Archive Collected Data). But the main differentiators were:
- Autonomous execution within stages: GTG-1002 deployed Claude Code running on a Kali machine to orchestrate dozens of MCP tool operations autonomously — scanning and mapping dozens of internet-facing services during reconnaissance, then discovering internal admin portals, databases, logging servers, and temporal workflow systems once inside the network. The AI didn't just suggest commands; it executed them, making tactical decisions about what to probe next without waiting for operator input.
- Live exploitation and pivoting: Operating within GTG-1002’s scaffolding, the AI exploited an SSRF vulnerability in a public-facing web server to proxy commands into the internal cloud environment, harvested SSH private keys from internal infrastructure and service account tokens from cloud metadata services and AWS Secrets Manager, and used those harvested credentials to move laterally across the victim's cloud environment. These are the operational phases (discovery → credential access → lateral movement) that were more rare in our dataset.
- Human intent, AI execution: GTG-1002 provided strategic direction while the AI handled tactical implementation. The AI operated autonomously during reconnaissance and internal discovery, adapted its approach when it encountered unanticipated infrastructure like container image signing workflows and service account identities, and staged and compressed tens of thousands of proprietary workflow records and internal architecture documentation for exfiltration. The final data extraction — downloading to the attacker's machine via curl MCP tool calls — was human-directed, suggesting the operator retained control over the consequential decisions while delegating the operational work to the AI.
GTG-1002’s activity was novel for using an AI agent to autonomously chain together many stages of the cyberattack lifecycle—reconnaissance, exploitation, lateral movement, and exfiltration—into a coherent operation, making real-time decisions about what to do and what data to collect. This is the dimension of AI-enabled uplift that a technique-frequency table cannot capture, and it is the dimension we expect to matter most as agentic tooling matures.
How we are using the Navigator to inform our safeguards
The findings in this report have shaped how we detect, investigate, and disrupt AI-enabled cyber misuse.
First, our risk scores show that the highest-risk actors are not always the loudest or the most prolific—they often appear ordinary in terms of the type and volume of techniques they employ, and instead are distinguished by how they orchestrate their AI to carry out an entire cyber operation. We are updating our detection systems accordingly, expanding our classifiers and probes to catch techniques that correlate with high ARiES scores. We’re also developing detection signals for agentic misuse patterns that don’t map cleanly to MITRE, such as multistep autonomous execution, AI-directed pivot decisions, and tool-augmented operations through MCP servers and similar interfaces.
Second, we have rolled out real-time cyber safeguards on our most capable models that automatically detect and block prohibited activity (such as ransomware development or mass data exfiltration) at the request level. We are also now routing higher-risk dual-use activities—those that both cyberattackers and defenders may undertake—through our Cyber Verification Program (CVP), which allows defensive practitioners to continue using our models in their work.
Third, through Project Glasswing, we are studying the offensive cyber capabilities of our most capable model before making it available to the wider public, so that we understand where AI cyber capabilities are heading before threat actors can make use of them, and can design safeguards before such misuse happens.
Finally, following on from our collaboration with Verizon on the 2026 Data Breach Investigation Report, we are now in active conversations with MITRE about how the ATT&CK framework can evolve to capture the AI-native operational behaviors we observed in this analysis. We also continue to share technical indicators; tactics, techniques, and procedures used by threat actors; and investigative findings with our partners in government and industry on an ongoing basis.
A new era for MITRE ATT&CK
The most dangerous actors are now using AI to orchestrate attacks rather than simply build tools that enable such attacks, and the framework threat investigators use to track threats has yet to catch up. Traditional frameworks that bank on actors being technically sophisticated will fail when low-skill actors can build, command, and operate expert-level harnesses.
One clear lesson from a year of mapping this activity, as well as our work with Verizon, is that we must expand our shared threat vocabulary. The MITRE ATT&CK captures the individual techniques actors execute, but the behaviors that distinguish the highest-risk actors from others—things like agentic orchestration of an entire killchain, or the autonomous selection of targets—are not yet captured by this taxonomy.
We believe the next step is to add new cross-cutting categories to the ATT&CK framework that help threat investigators identify the agentic, autonomous, and decision-making behaviors that chain multiple techniques together. This will give defenders a vocabulary that keeps pace with how adversaries are using AI tools in the wild.
At the same time, it is clear that defenders will need to use AI with the same sophistication and urgency as attackers, share threat intelligence between organizations, and shorten the time from identifying a software vulnerability to patching it. As an industry, we must become much less tolerant of insecure code. The transitional period will be difficult. But, if industry, government, and civil society treat the current moment with the urgency it warrants, we believe capable AI systems will benefit defenders more than attackers in the long run: finding bugs before new code ships, and making the systems societies depend on more secure. The result could be better-defended infrastructure, and a digital environment with materially less fraud and abuse. We will continue to publish what we learn as the threat landscape evolves.
Footnotes
[1] For the DBIR, we provided analysis of 11 months of threat actor data, and rounded this out to 12 months for this report.
[2] We observe sub-techniques from both the Enterprise and the Mobile technique matrices from MITRE. Enterprise techniques account for 99% of observations.